
The creation and development of copyright law are closely connected to technological and associated business transformations (see, e.g. here). It is therefore not surprising that progress in AI technologies and their deployment in the creative sector creates new opportunities and challenges for the law, creators (authors and performers), and rightsholders. What is perhaps different with AI technologies is the magnitude of the potential impact, brought about by the unprecedented scale of automation that increases productivity and access to creativity. Yet, the very same automation poses challenges for the application of copyright law, increasing legal uncertainty, as demonstrated in this report vis-à-vis AI music outputs. This begs the question of how EU law can and should meet this challenge.
A recent report in the context of the reCreating Europe project addresses this question, building on previous work from some of its authors, namely a study on “Trends and Developments in Artificial Intelligence: Challenges to IP” (summarised in a previous post) and this article. Readers interested in the topic, should also note another important study on copyright and AI conducted in parallel and just released by the team of Alain Strowel, Sari Depreeuw, Luc Desaunettes-Barbero et al., as a part of a larger study on copyright and new technologies for the European Commission.
The focus of our report is on what we call AI music outputs, meaning any kind of music-related content generated by or with the assistance of AI systems, tools and techniques. The report complements the analysis of laws with a review of practices and contractual arrangements of claiming and attributing authorship and/or ownership by actors in the field of AI music creation. The study covers practices of for-profit AI-powered online music creation services (e.g., AIVA, Endel, Xhail, Boomy, Score/Amper, Jukebox, MuseNet, AI tools of Sony CSL) and of non-profit AI music research projects (e.g., folk-rnn, Melomics).
This two-part blog post contains a summary of our report’s conclusions and recommendations. Part I summarises the conclusions of our research on how EU copyright rules apply to AI music outputs. Part II will present our conclusions regarding EU rules on related rights and outline policy recommendations for EU legislators in this field.
A piece of AI music output created with one click on a button specifically for this blog post using folk-rnn could be enjoyed here: https://themachinefolksession.org/tune/1114
Copyright protection and authorship of AI music outputs
Under international and EU copyright law, authors are granted protection automatically upon the creation of original works. There were always situations where doubts subsist about the originality of created subject matter and the identity of their authors. The main difference brought about by the increasing deployment of AI systems, tools and techniques in the creative process is the scale and frequency of situations where there is uncertainty about: (i) the copyright protection of content produced; and (ii) the authorship status of the persons involved at different stages of that process (e.g., developers and/or users). This uncertainty is rooted in the technical nature and operation of AI systems, namely of the machine learning type, which erode the (causal, creative and expressive) link between the human contribution to or intervention in the process and the output generated by (or with the assistance of) the AI system.
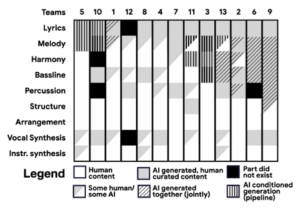
An overview of how the 13 teams of the 2020 AI Song Contest considered human and AI roles in different music building blocks (source)
Based on an analysis of international and EU law, including the case law of the CJEU, it is possible to identify a four-step test for the assessment of copyright protection of subject matter as a “work”. This test, conceptualised in prior research (here and here) and further developed in the current study, can be used to assess whether AI output qualifies as a work from the perspective of EU law. The four interrelated criteria that subject matter such as an AI output should meet to qualify as a copyright-protected “work” are as follows: (1) a “production in the literary, scientific or artistic domain”; (2) the product of human intellectual effort; (3) the result of creative choices; and (4) the choices “expressed” in the output.
In our analysis, we applied this test to AI musical outputs. The domain of music was selected for different reasons: it is one of the creative fields where the deployment of AI technology is the most significant; it contains a diversity of applicable legal rules (including related rights) in EU copyright law; and due to its economic and cultural significance, this field often acts as a catalyst for legal and policy changes in the area of copyright.
Our analysis shows that many of the AI music outputs examined will likely pass steps (1), (2) and (4) unscathed. The crux of the test is therefore in step (3), which encapsulates the essence of the originality standard under EU copyright law. From this perspective then, where an output does not qualify as original in the sense that it reflects the author’s free and creative choices, that output is – from the perspective of copyright – in the public domain. As noted below, however, it might still benefit from protection under related rights.
In the context of step (3), it is possible in the first place to identify a series of external constraints on the assessment of originality: rule-based, technical, functional, and informational. The existence of such constraints reduces the author’s margin for creative freedom, sometimes below the originality threshold. In the second place, the step allows for the identification of three iterative stages of the creative process when using an AI system: “conception”, “execution”, and “redaction”. This approach maps well to the basic definition of AI systems used in our analysis, particularly to machine learning systems.
From our analysis, it results that the most relevant human contributions for purposes of an assessment of originality take place at the “conception” and “redaction” stages, rather than the execution stage. Furthermore, the iterative nature of the process means that a determination of originality requires a case-by-case assessment, for which there might not always be readily available public information. The result is that questions of originality – as well as authorship and ownership – in these cases will prima facie be governed by the operation of legal presumptions. Hence, absent additional transparency measures, an accurate substantive assessment of originality will require reverse engineering of the human interventions or contributions in the use of the AI system leading to a certain output.
Our analysis of the concept of work also investigated the legal status of secondary (derivative) works in relation to the (primary) works used in the input in the context of AI music outputs. In our view, subject to specific unharmonized national provisions to the contrary, works created with the aid of AI systems are generally not, as such, secondary (derivative) works in relation to the primary works used in the input if they do not reproduce any original elements of the primary works. From our understanding of AI technology (and in particular of machine learning systems), such a reproduction does not occur in a technical or legal sense in such a way as to influence the qualification of the output as a secondary (derivative) works; rather, eventual similarities between the output and a pre-existing (original) work would mostly matter for analysis in the context of an infringement assessment.[1] (On the topic of AI outputs and derivative works, see here.)
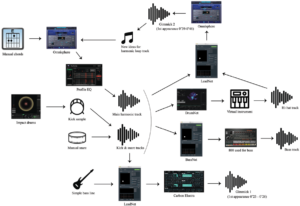
Example workflow diagram by artist duo Hyper Music. The diagram shows how various AI tool prototypes of Sony CSL are used in the music production process (source)
After examining the criteria for protection, our analysis then explored private actors’ practices of claiming copyright protection and attributing authorship in the domain of music, including through contractual means. The case studies and interviews carried out in our research allowed us to identify areas of uncertainty and/or errors with legal qualifications regarding the subsistence of copyright protection and/or authorship in practice. The issue is manifested through the fact that claims to authorship and/or ownership are often associated with the nature (commercial/non-commercial) of AI music creation projects rather than with a facts-based analysis of the creative processes.
Originality and authorship are matters of public law, leaving private parties with limited margin for interpreting the legal significance of their actions in the creative process. It is therefore a matter of law whether a particular output is a work protected by copyright. Still, in some cases, there is likely an issue of legal qualification when an online AI music creation service offers its users a variety of options for making choices at different stages of the creative process but ignores the actual choices made when attributing authorship (e.g., by contractually always attributing authorship to the same person). Similarly indicative of uncertainty or errors in legal qualification is the situation where choices of users of online AI music creation services are limited by the functionality of the services (e.g., regarding the setting of some parameters and postproduction editing), but authorship is systematically attributed to different parties in the process (e.g., developer or user).
The uncertainty is compounded by the fact there are currently no typical or uniform contractual clauses used by all or most AI service providers. This situation can probably be explained by the absence of clear legal rules and/or authoritative precedents in this regard. Our research suggests that this state of uncertainty is a global problem. The examination of AI projects’ geographic locations, literature review and interviews identified no meaningful relation between national/regional legal copyright regimes relevant for AI music creation and choices of countries for establishing AI music projects. Instead, factors like overall business and investment climate, public grants and taxation seem to play an important role.
Our legal analysis of authorship of AI musical outputs suggests that it is useful to distinguish between two scenarios. The first scenario refers to the situation when AI developers and users are the same person(s), whereas the second refers to cases when AI music creation systems are offered to users “as a service”. The second scenario is more complex as regards establishing authorship of the persons involved in the creative process, since it requires an understanding of functional freedom enjoyed by users, as well as the specific choices made by all persons involved in the creative process. The proposed four-step test facilitates the qualification of AI outputs under copyright.
As in the case of creating with traditional means, the recognition of copyright protection and authorship to works created by or with the assistance of AI systems is not subject to artists disclosing and documenting the creative process. Naturally, the persons directly involved in the creation are mostly well-informed about the factual circumstances surrounding the production of an AI output. Still, even when detailed records of the creative process are available, there are often issues with the certainty of legal qualifications.
Legal presumptions of authorship and ownership – like those in the Berne Convention and Enforcement Directive – may shift the burden of proof for someone challenging the identity of a human author (of his or her actual authorship) but they are much less likely to help determine whether an AI output is actually original and copyright-protected. They can be used by economic actors to deviate from a legally accurate attribution of rights, which is necessarily fact-specific. Persons with such factual knowledge and control over the publication of the output have therefore the possibility to claim authorship and ownership of such content, even if the same lacks originality from the perspective of copyright law. In other words, while the presumption of authorship helps with addressing the problem of lack of information on the creative process characteristic of AI outputs, it also enables false authorship and ownership claims that may inter alia cause the extension of copyright protection in practice to AI-generated outputs that should be unprotected and, therefore, in the public domain.
The answers to this problem would then need to be found in the fact-finding that form part of eventual litigation process. To be sure, this is limited solution to the problem of false authorship and ownership claims in relation to AI outputs.
This research is part of the reCreating Europe project, which has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 870626.
[1] Our research did not examine issues of reproduction of works for the purpose of training AI systems.
________________________
To make sure you do not miss out on regular updates from the Kluwer Copyright Blog, please subscribe here.

